Transolver vs MeshGraphNet pour ZienkiFlowNet — étude comparative d'une architecture attention-based
Remplacer le MeshGraphNet de ZienkiFlowNet par un Transolver à double branche : 2× moins de paramètres, meilleur sur la pression et le débit, moins bon sur la vitesse — analyse complète.
L'article précédent présentait ZienkiFlowNet, un réseau de neurones sur graphes (MeshGraphNet, MGN) pour prédire des écoulements 2D. Ce nouveau billet documente une expérience d'architecture : remplacer le processeur MGN par un Transolver (Wu et al., ICML 2024), une famille de modèles fondée sur l'attention plutôt que sur la propagation locale de messages. À budget paramétrique divisé par deux, le Transolver-Dual égale ou dépasse le MGN sur la pression et le débit, mais reste environ 1,7× moins précis sur le champ de vitesse. Voici pourquoi.
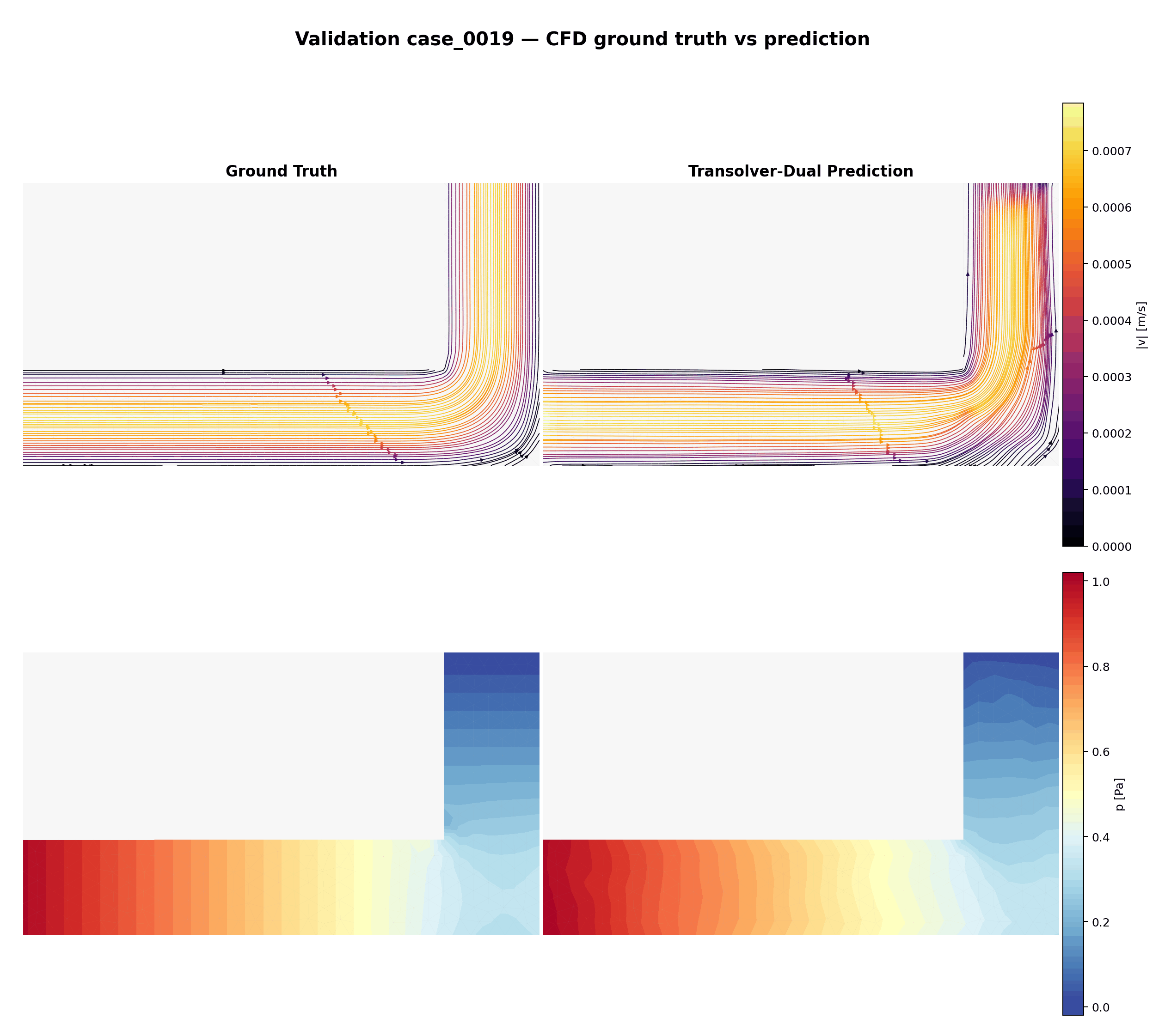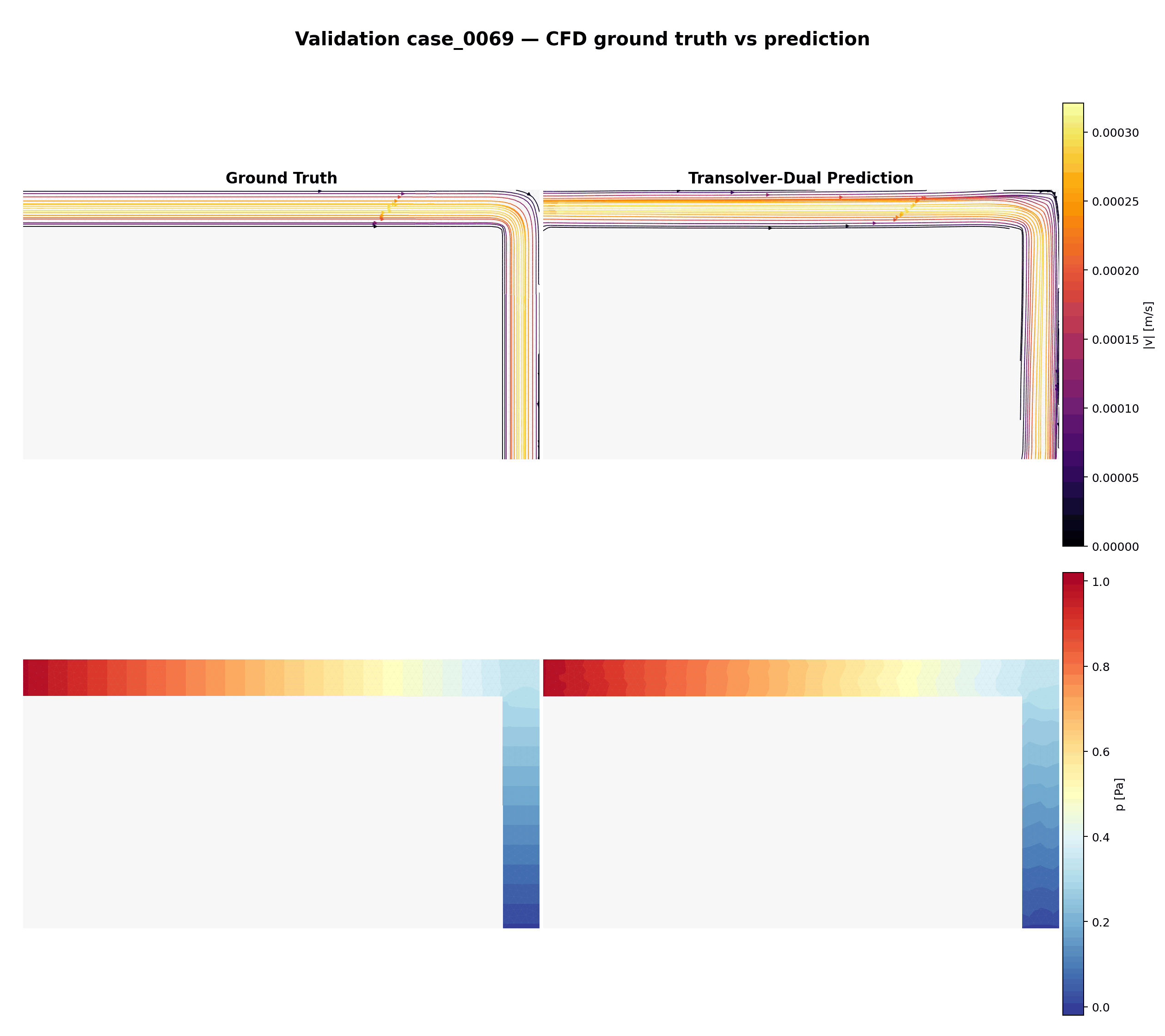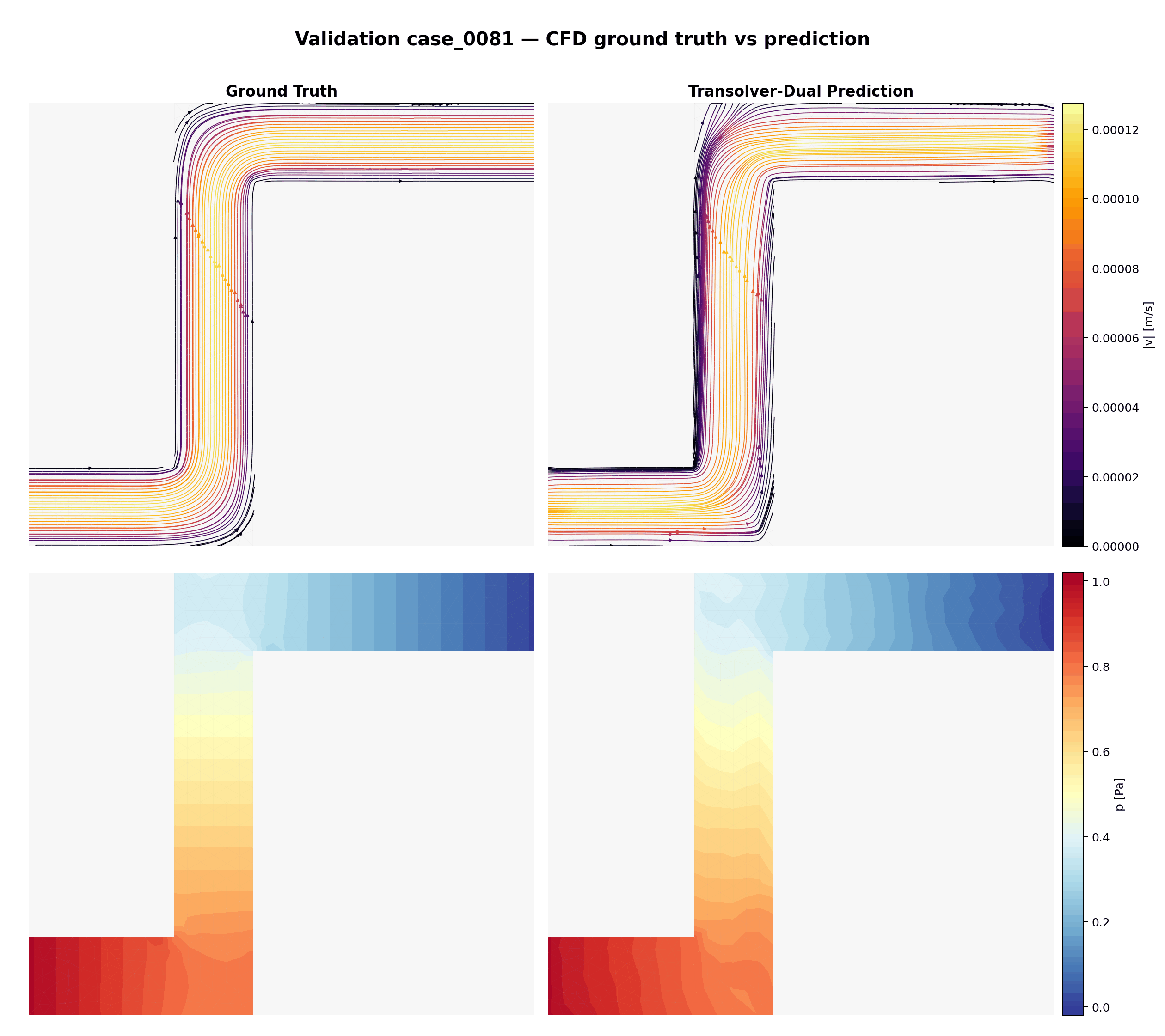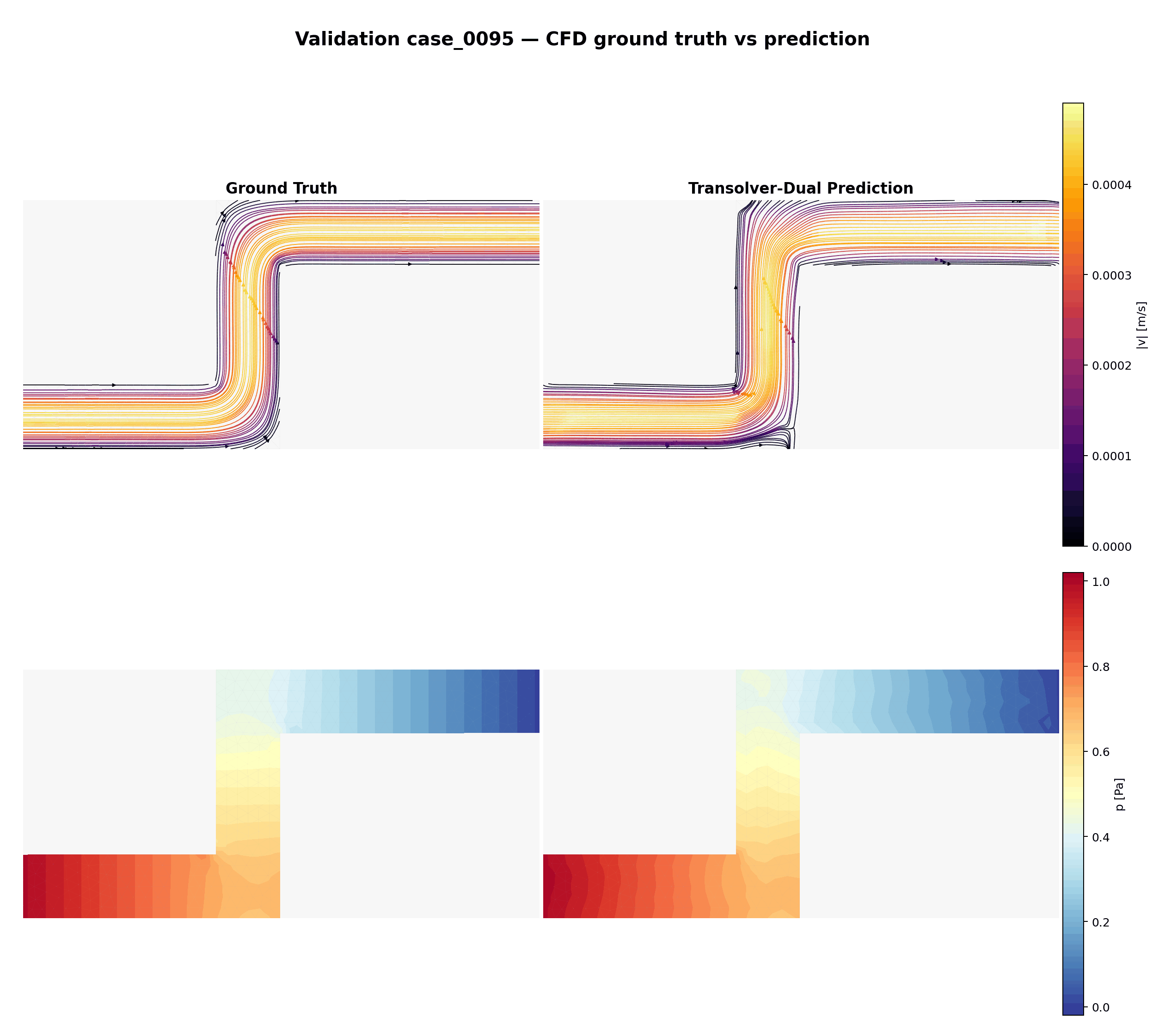
Boucle animée sur les 15 cas de validation — vérité terrain (CFD) vs prédiction Transolver-Dual. Ligne du haut : lignes de courant colorées par magnitude de vitesse. Ligne du bas : champ de pression.
1. Contexte et motivation
La configuration de référence de ZienkiFlowNet (cmp_dual_token_v6_p_bothpe_vort_eq7) repose sur un MGN dual : un encodeur partagé, une branche champ (UNet sur graphe avec attention pariétale) et une branche scalaire pour le débit . Sur les 15 cas de validation, elle atteint :
Ses ingrédients principaux :
- un message passing local de type MGN, fournissant un biais inductif fort pour les gradients pariétaux ;
- une attention globale par tokens et une attention pariétale dédiée ;
- un repère équivariant local (mode
wall_only) pour décoder la vitesse en base tangente/normale aux parois ; - une séparation des têtes vitesse et pression, avec
pressure_hidden_mult = 2.
L'objet de cette étude est de quantifier l'apport d'une famille architecturale distincte, fondée sur l'attention plutôt que sur la propagation locale. Les Transolver remplacent le passage de messages par une attention entre slice tokens, où chaque slice constitue une partition douce de la géométrie, apprise conjointement à la solution.
2. Méthodologie
a) Le bloc Physics-Attention
Chaque bloc Transolver enchaîne quatre opérations :
(1) Assignation douce. Pour chaque nœud et chaque tête , un MLP produit un vecteur de probabilités sur slices :
(2) Agrégation. Les features sont moyennées par slice selon ces poids :
(3) Attention multi-têtes entre les tokens de slice. Le coût est en et non en .
(4) Diffusion retour vers les nœuds via les mêmes poids , suivie d'un FFN et de connexions résiduelles.
La construction est mesh-free : ni edge_index ni cells n'interviennent dans le processeur. L'information géométrique pénètre exclusivement par l'encodeur (pos, lap_pe, x_geom, wall_normal).
b) Architecture JEPATransolverDual
Une première itération mono-branche à 16 slices s'étant révélée insuffisante sur le champ de vitesse (cf. section 3), la stratégie dual de la référence MGN a été transposée au cadre Transolver :

Panneau A : flot de données — entrées, encodeurs, tronc partagé, branches V et P, décodeurs, projection BC, sorties. Panneau B : détail interne d'un bloc Physics-Attention (assignation → agrégation → MHA inter-slices → diffusion retour, avec LayerNorm, FFN et résidus).
Les choix architecturaux notables :
- Asymétrie de slices entre branches : pour la vitesse (résolution fine près des parois), pour la pression (champ approximativement harmonique en régime de Stokes).
velocity_local_basis = Trueetequivariant_frame_kind = wall_only: aux nœuds pariétaux, la vitesse est décodée dans la base , ce qui rend la condition de non-glissement structurellement satisfaite.- Head rattachée à la branche vitesse, conformément à la définition .
c) Taille des modèles
Les architectures comparées présentent des budgets paramétriques contrastés :
| Modèle | Paramètres | Ratio vs eq7 |
|---|---|---|
| eq7 (MGN dual, référence) | 1,10 M | 1,00 × |
| Transolver simple () | 0,31 M | 0,28 × |
| Transolver-Dual | 0,51 M | 0,46 × |
Le Transolver-Dual est ainsi environ 2,2× plus compact que le MGN de référence, malgré sa structure à deux branches. Cette compacité résulte de l'absence de paramètres associés aux arêtes du maillage (pas de MLP de message passing) et du coût en de l'attention inter-slices, indépendant de la taille du maillage. Le facteur de compression atteint ~3,5× pour la variante mono-branche. Les comparaisons de performance qui suivent sont donc à mettre en regard de cette différence de capacité.
d) Entraînement
Le protocole reprend à l'identique celui utilisé pour la référence MGN :
- recuit cosinus du taux de masquage () sur les features observables ;
- projection des conditions aux limites en espace normalisé (
project_bcs_scaled) ; - fonction de coût : MSE nœud + erreur sur + pénalisation de divergence et de vorticité + pondération de la pression () ;
- 180 époques, batch 8, lr , warmup 5.
Le cache de données utilisé est la version v10 (9 features par nœud, sans geo_inlet, geo_outlet ni flow_tangent de la v9). Le baseline strictement équivalent est donc eq7_ablA, entraîné sur ce même cache.
3. Résultats
Les statistiques par cas sont calculées sur le split de validation (15 cas, masque à 100 %, conditions aux limites projetées) :
| Run | Params | Époques | % (med / mean / max) | % (med / mean / max) | (mean) |
|---|---|---|---|---|---|
| eq7 (MGN, 12 feat) | 1,10 M | 120 | 5,46 / 6,57 / 16,89 | 1,75 / 1,64 / 2,29 | 4,0 × 10⁻⁹ |
| eq7_ablA (MGN, 9 feat) | 1,10 M | 120 | 4,77 / 6,34 / 19,15 | 1,57 / 1,57 / 2,15 | 7,6 × 10⁻⁹ |
| Transolver simple () | 0,31 M | 120 | 11,98 / 11,66 / 17,11 | 1,82 / 1,84 / 3,16 | 7,3 × 10⁻⁹ |
| Transolver-Dual | 0,51 M | 180 | 11,58 / 10,79 / 16,66 | 1,66 / 1,52 / 2,27 | 5,4 × 10⁻⁹ |

Courbes , et val_node_MSE pour les quatre runs. Le Transolver-Dual converge plus lentement que le MGN mais atteint à 180 époques un plateau stable sur la pression et le débit.
a) Apport de la double branche
À cache équivalent, le passage de Transolver simple à Transolver-Dual entraîne :
- une réduction de 7 % de moyenne (11,66 → 10,79) ;
- une réduction de 17 % de moyenne (1,84 → 1,52) ;
- une réduction de 25 % de (7,3 → 5,4 × 10⁻⁹).
Le bénéfice porte principalement sur la pression et le débit, en accord avec l'hypothèse selon laquelle ces deux quantités requièrent un nombre de modes globaux distinct de celui du champ de vitesse.
b) Comparaison avec MGN
À cache strictement équivalent (eq7_ablA, 9 features) :
- Pression : Transolver-Dual obtient une erreur moyenne inférieure (1,52 % vs 1,57 %) et un maximum comparable (2,27 % vs 2,15 %).
- Débit : Transolver-Dual obtient une erreur moyenne inférieure (5,4 × 10⁻⁹ vs 7,6 × 10⁻⁹) et un maximum également inférieur (3,0 × 10⁻⁸ vs 3,2 × 10⁻⁸).
- Vitesse : le MGN reste supérieur (6,34 % vs 10,79 % en moyenne, facteur ~1,7).
Ces résultats sont obtenus avec un Transolver-Dual environ deux fois plus compact en paramètres que la référence MGN. Rapporté à la capacité du modèle, le Transolver-Dual présente donc un meilleur rendement paramétrique sur et sur , et un rendement comparable sur la vitesse.
c) Interprétation
Le Transolver-Dual a convergé à 180 époques (variation de inférieure à 0,1 % entre les époques 150 et 180). Les valeurs maximales de sont comparables entre les deux familles (~17 %), ce qui indique que l'écart observé sur la vitesse n'est pas imputable à un cas pathologique isolé mais à un déficit systématique.
Une explication structurelle peut être avancée : avec 32 slices pour environ 1,5 k nœuds, chaque slice agrège en moyenne ~47 nœuds, soit une résolution effective approximativement 6× plus grossière qu'un MGN local à 6 hops. Les couches limites, les zones de recirculation en aval des coins et les gradients pariétaux raides sont mal reconstruits à cette résolution en l'absence d'un biais inductif local.
Inversement, la pression — approximativement harmonique en régime de Stokes bas-Re — est bien représentée par les modes globaux que capturent 8 slices. Le débit , intégrale globale sur l'inlet, bénéficie également de cette représentation globale.
4. Conclusion
La double branche est nécessaire pour rendre l'architecture Transolver compétitive sur ce problème, comme c'était déjà le cas pour le MGN. L'allocation asymétrique du nombre de slices entre les branches (32 pour , 8 pour ) permet d'adapter la capacité du modèle à la régularité de chaque champ.
Avec un budget de paramètres deux fois moindre que la référence MGN, le Transolver-Dual améliore les métriques de pression et de débit, mais demeure environ 1,7× moins précis sur le champ de vitesse. Pour ce jeu de données, où la résolution fine de la vitesse pariétale est déterminante, le biais inductif local du MGN reste avantageux.
Une architecture hybride combinant quelques blocs MGN locaux en tête de la branche Transolver (étape 1ter) constitue une perspective naturelle pour réunir les bénéfices des deux paradigmes : la précision pariétale de la propagation locale, et l'efficacité paramétrique de l'attention par tokens.
Référence : Wu et al., Transolver: A Fast Transformer Solver for PDEs on General Geometries, ICML 2024.